This post houses my continuously developing view about ML research. I may update it from time to time
One of my professors once said: “Rather than pure science, machine learning is really an engineering science.” I feel like I understand this statement more and more as time passes.
There are several angles from which I’ve found it resonating with my research experience:
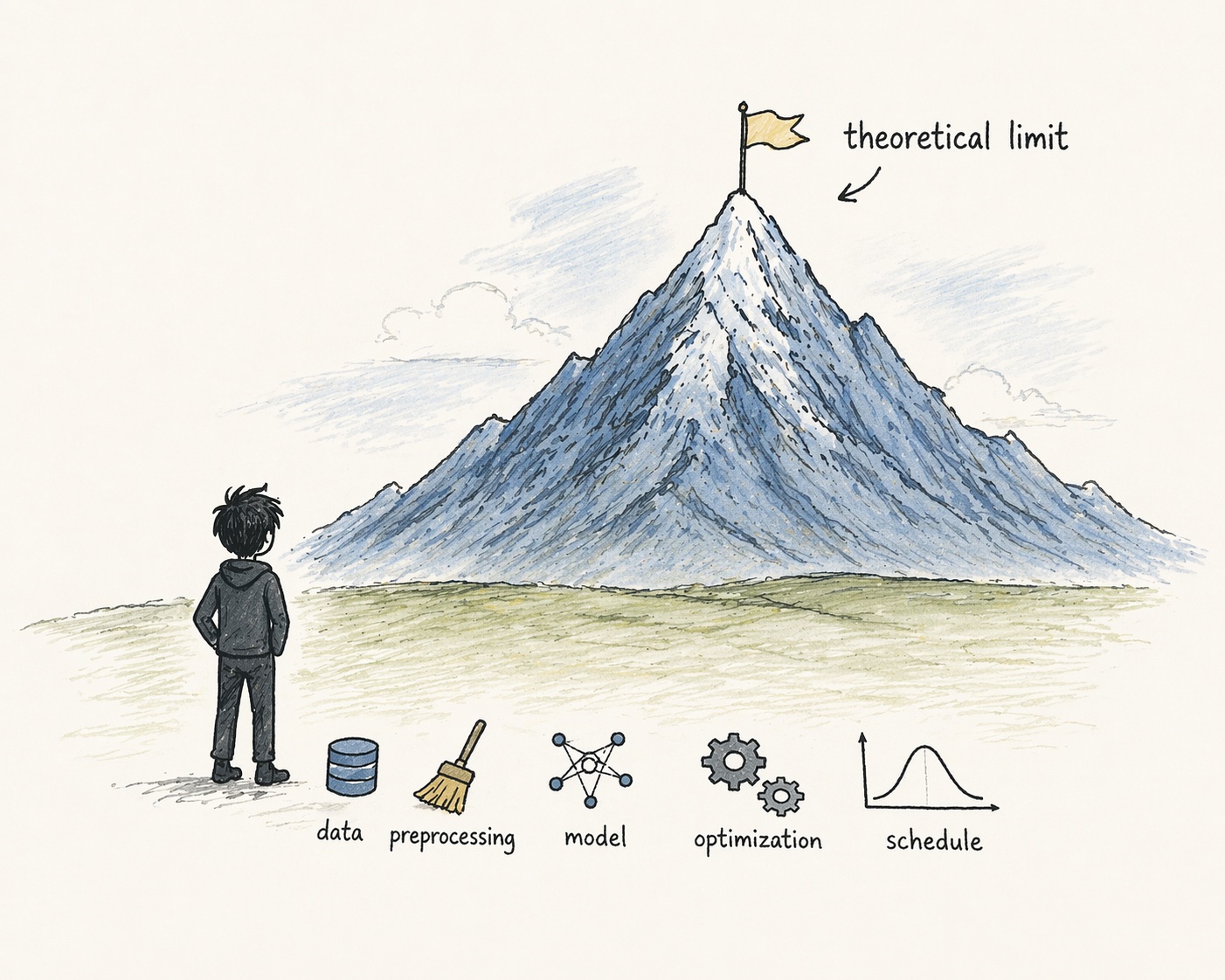
- When building ML models, while mathematical theory defines the ceiling, engineering determines your baseline. In principle, the theory of diffusion + universal function approximation should allow us to model many arbitrary distributions with a large enough model. In practice, training dynamics are shaped by your design choices: data preprocessing, noise schedule, model architecture. All of these play a role and form the structural bias that supports that theoretical outcome. Small deviations from theoretical correctness in the model or loss often still lead to workable solutions (e.g. variational lower bound term weighting in diffusion training), but a difficult data distribution due to under-invested preprocessing design can completely break training.
- Theory often lags behind practice in this field. Many successful methods were discovered empirically first, and only later understood in terms of a governing theory. As a researcher, you often have to act on an empirical basis. Batch Normalization is a good example: it was widely adopted before a stable theoretical explanation emerged, and even today it is explained through multiple incomplete perspectives.
- When learning a new modelling concept, I find that I develop my understanding more efficiently by starting with the intuitions behind the initial engineering choices and their iteration chronology, rather than jumping straight into the latest, more distilled, unified theory. The former helps me see the rationale and design space considered by the original authors, and build stronger intuitions about which components are fundamental to training dynamics. Again, I have to mention my journey in learning diffusion models. While there are well-written resources for understanding diffusion through a unified stochastic differential equation lens, I found myself understanding the subject better after going through it in the order of latent variable model framing (DDPM, variational diffusion models), score models, and finally the SDE work that unifies these views.
Ok, enough ranting. Time to go back to figuring out why my loss refuses to go down…